Implementation of an efficient hierarchical agglomerative clustering algorithm
Interested? Contact muehlhaus@bio.uni-kl.de or venn@bio.uni-kl.de
Table of contents
Introduction
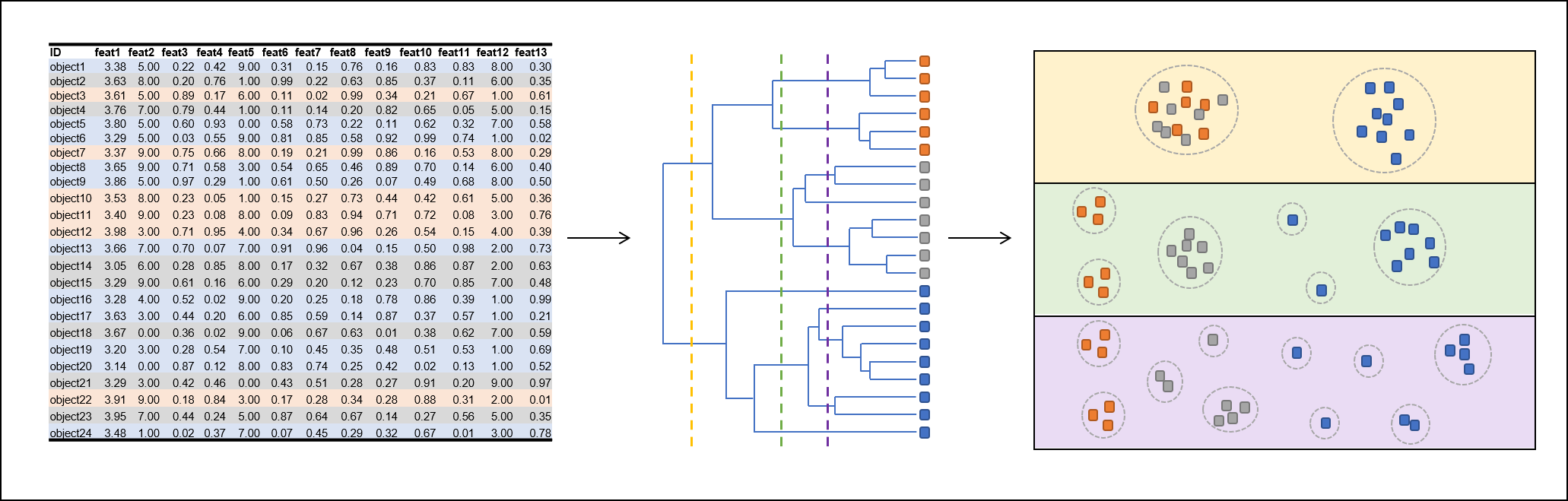
Fig 1: Generating a hierarchical tree structure from a complex data set. Vertical thresholds (yellow, green, violet) generate different cluster numbers.
Clustering methods can be used to group elements of a huge data set based on their similarity. Elements sharing similar properties cluster together and can be reported as coherent group. These properties could be e.g. (a) similar gene expression kinetics in time series, (b) similar physicochemical properties, (c) genetic similarity measures for phylogenetic trees, etc.
Many clustering algorithms require a predefined cluster number, that has to be provided by the experimenter. The most common approach is k-means clustering, where k stands for the user defined cluster number. This kind of user interaction can lead to results, that are not objective, but highly influenced by the view and expectation of the experimenter.
Hierarchical clustering (hClust) does not require such cluster number definition. Instead, hClust reports all possible cluster numbers (One big cluster with all elements to n clusters where every element is a singleton in its own cluster) in a tree structure (Fig 1). A hClust tree has a single cluster (node) on its root and recursively splits up into clusters of elements that are more similar to each other than to elements of other clusters. For generating multiple cluster results with different number of clusters, the clustering has to performed only once. Subsequently the tree can be cut at any vertical line which will result in a defined number of clusters.
There are two types of hClust:
Agglomerative (bottom-up): Each data point is in its own cluster and the nearest ones are merged recursively. It is referred to agglomerative hierarchical clustering (HAC)
- Divisive (top-down): All data points are in the same cluster and you divide the cluster into two that are far away from each other.
- The presented implementation is an agglomerative type.
There are several distance metrics, that can be used as distance function. The commonly used one probably is Euclidean distance. By inverting the distance, you end up with a similarity. High similarities indicate low distances, and vice versa. By calculating the similarities for every element pair, a similarity matrix can be generated.
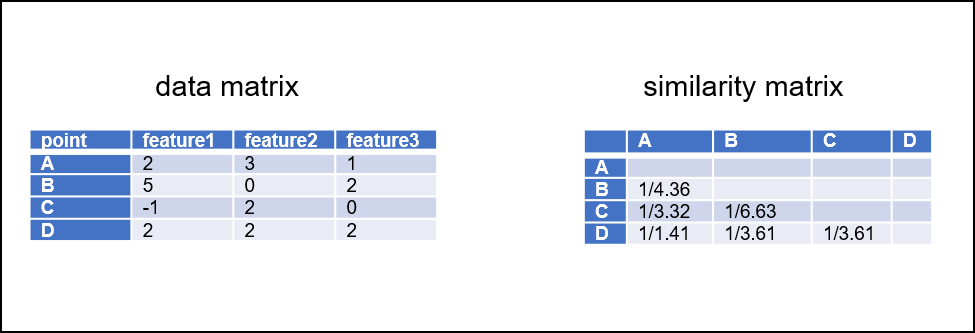
Fig 2: Data matrix (left) with measurement types as columns and (biological) entities as rows. The data matrix can be converted into a similarity matrix, that contain the inverse of distances.
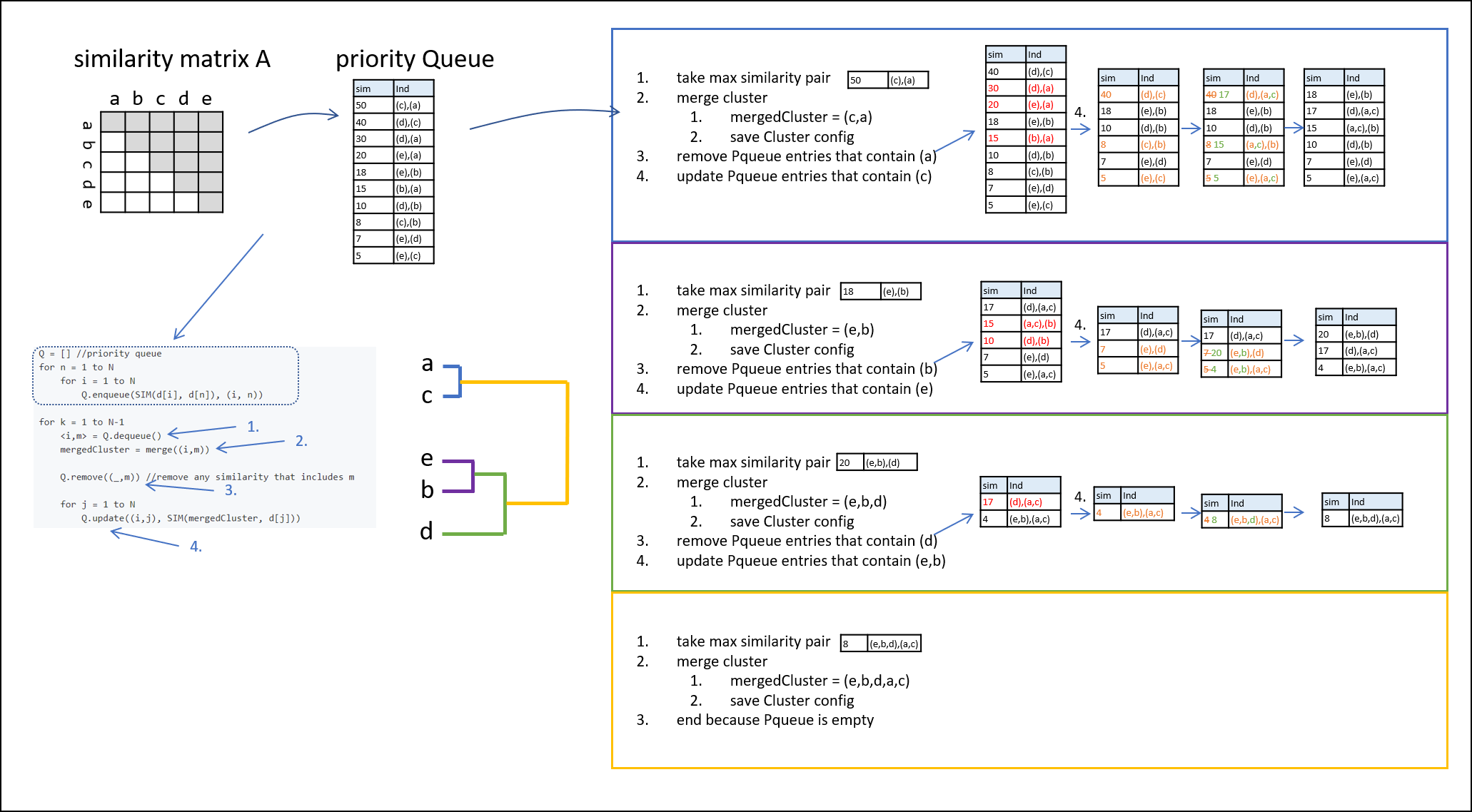
Fig 3: Workflow as proposed in pseudo code in Reference#2.
Aim for this project
- Blog post introducing the method, its applications, and limitations.
- Implement an efficient agglomerative hierarchical clustering in FSharp.Stats.
Coding clues
0th step:
-
Inform yourself about
- queues and priority queues (roughly)
- similarity measurements such as Euclidean distance, Manhattan distance, the advantage to use the squared Euclidean distance
- single linkage, complete linkage, and centroid based linkage types
-
Down below you can see the pseudo code (not F#!) the efficient agglomerative hierarchical clustering (HAC) is based on:
// Generating priority queue Q = [] //priority queue for n = 1 to N for i = 1 to N Q.enqueue(SIM(d[i], d[n]), (i, n)) // iterative agglomerative clustering for k = 1 to N-1 <i,m> = Q.dequeue() mergedCluster = merge((i,m)) Q.remove((_,m)) //remove any similarity that includes m for j = 1 to N Q.update((i,j), SIM(mergedCluster, d[j]))
1st step:
create a F# script (.fsx), load and open
FSharp.Stats,FSharpAuxandFSharpx.Collections-
import test data
You can find the classic clustering dataset "iris" here.
- An implementation of an priority queue is given below.
-
Please read this project description carefully before starting the implementation steps. A modification given in Reference#2. that boosts the efficiancy is not covered by the steps below. See the "7: Further coding considerations" in the end!
#r "nuget: FSharpAux, 1.1.0"
#r "nuget: FSharp.Stats, 0.4.3"
#r "nuget: FSharpx.Collections, 2.1.3"
#r "nuget: Plotly.NET, 2.0.0-preview.16"
open FSharp.Stats
open FSharpAux
open FSharpx.Collections
open Plotly.NET
let lables,data =
let fromFileWithSep (separator:char) (filePath) =
// The function is implemented using a sequence expression
seq { let sr = System.IO.File.OpenText(filePath)
while not sr.EndOfStream do
let line = sr.ReadLine()
let words = line.Split separator//[|',';' ';'\t'|]
yield words }
fromFileWithSep ',' (__SOURCE_DIRECTORY__ + "../content/irisData.csv")
|> Seq.skip 1
|> Seq.map (fun arr -> arr.[4], [| float arr.[0]; float arr.[1]; float arr.[2]; float arr.[3]; |])
|> Seq.toArray
|> FSharp.Stats.Array.shuffleFisherYates
|> Array.mapi (fun i (lable,data) -> sprintf "%s_%i" lable i, data)
|> Array.unzip
type PriorityQueue<'T when 'T : comparison>(values : 'T [], comparisonF : 'T -> float) =
let sort = Array.sortByDescending comparisonF
let mutable data = sort values
new (comparisonF) = PriorityQueue(Array.empty,comparisonF)
interface System.Collections.IEnumerable with
member this.GetEnumerator() = data.GetEnumerator()
member this.UpdateElement (t:'T) (newt:'T) =
let updated =
data
|> Array.map (fun x -> if x = t then newt else x)
|> sort
data <- updated
member this.Elements = data
member this.RemoveElement (t:'T) =
let filtered =
Array.filter (fun x -> x <> t) data
data <- filtered
member this.GetHead :'T =
Array.head data
member this.Dequeue() =
let head,tail = Array.head data, Array.tail data
data <- tail
head, this
member this.Insert (t:'T) =
let newd = Array.append data [|t|] |> sort
data <- newd
member this.UpdateBy (updateElementFunction: 'T -> 'T) =
let newd =
Array.map updateElementFunction data
|> sort
data <- newd
member this.RemoveElementsBy (predicate: 'T -> bool) =
let newd =
Array.filter predicate data
data <- newd
2nd step: Generate priority queue
-
For each data point calculate the distances to each of the other points.
You can find different kinds of distance measures in
ML.DistanceMetrics-
Similarity can be interpreted as inverse distance. The lower the distance, the higher the similarity and the faster the data points have to be merged. An appropriate type to store the result could be the following:
/// Type to store similarities
type Neighbour = {
/// inverse of distance
Similarity: float
/// list of source cluster indices
Source : int list
/// list of target cluster indices
Target : int list
}
with static
member Create d s t = { Similarity = d; Source = s; Target = t}
//Example queue
let neighbours =
[|
Neighbour.Create 1. [1] [2]
Neighbour.Create 2. [0] [6]
Neighbour.Create 5. [3] [5]
Neighbour.Create 2. [4;7;10] [8;9]
Neighbour.Create 7. [1] [2]
|]
////// usage of PriorityQueue
let myPQueue = PriorityQueue(neighbours,fun x -> x.Similarity)
myPQueue.GetHead // reports queues
myPQueue.RemoveElement (Neighbour.Create 5. [3] [5]) // removes element from queue
myPQueue.UpdateElement (Neighbour.Create 2. [0] [6]) (Neighbour.Create 200. [0] [6]) // update element in queue
myPQueue.RemoveElementsBy (fun x -> not (List.contains 3 x.Source)) // update element in queue
myPQueue.UpdateBy (fun x -> if x.Similarity > 2. then Neighbour.Create 100. x.Source x.Target else x)// update elements in queue by given function
////// usage of IntervalHeap
#r "nuget: C5, 2.5.3"
open C5
let myHeap : IntervalHeap<Neighbour> = IntervalHeap(MemoryType.Normal)
myHeap.AddAll(neighbours) // adds array of neighbours
let max = myHeap.FindMax() // finds max value entry
myHeap.DeleteMax() // deletes max value entry
myHeap.Filter (fun x -> x.Similarity = 5.) // filters entries based on predicate function
- Some example applications of the PriorityQueue type are shown above.
- Generate a priority queue that is descending regarding the similarity.
3rd step:
-
Create a clustering list, that contains information of the current clustering state. This could be an
int list []where each of the lists contains indices of clustered data points. Since in the beginning all data points are in its own cluster the clustering list could look as follows:let clusteringList = [|[0];[1];[2];...[n-1]|]
-
When cluster 1 and 2 merge, the clustering list may look like this:
let clusteringList = [|[0];[1;2];[];...[n-1]|]
4th step:
- Now the agglomeration starts. Since every data point is in its own cluster, you can perform n-1 agglomeration (merging) steps before you result in a single cluster that contains all data points.
-
For each merge (1..n-1) do
-
take the first entry of the priority queue (the most similar clusters)
source indices = [i]
target indices = [j]
Create a new cluster, that contains the merged indices: [i;j]
- Save the new cluster configuration in your clustering list. Therefore you can add j to the ith cluster, and you can remove j from the jth cluster.
- Remove any entry from priority queue that contains j as target or source index.
-
Update all entries in priority queue that contain i as source or targe index:
- j has to be added to every cluster that contains i
- Replace the distances with new distances of the merged mergedCluster to all other clusters.
- repeat cycle with next merge
-
5th step:
-
Clustering list now contains all possible cluster configurations. Convert the clustering list into
a binary tree structure such as
ML.Unsupervised.HierarchicalClustering.Cluster<'a>
6th step: Function implementation in F#
- create a function, that contains all necessary helper functions in its body and takes the following parameters (suggestion):
Parameter name |
data type |
description |
|---|---|---|
data |
|
data |
distFu |
|
distance Function from |
linkageType |
|
linkage type that is used during clustering |
output |
|
7th step: Further coding considerations
-
Removing elements from the priority queue is slow. Is there a better way to avoid the deletion?
-
Reference#2 suggests:
There is a repeated removal from Q when i,m are merged. This can be avoided with a new implementation where we maintain multiple priority queues and find the maximum of each priority queue and pick the one with max value. We can ignore the priority queue for m. When considering amortized analysis of this algorithm, this efficiently performs the deletion and restricts the number of calls to Heapify algorithm.
maybe a Map(int[],bool), or a nested priority queue would be beneficial
- or another implementation of heap/priority queues like C5.IntervalHeap could be faster
-
References
Additional information
Testing
- apply hClust to a dataset of your choice
- optional: Test your results against implementations in R/Python or in the best case against the datasets proposed in the original publication.
Blog post
- What is solved by the usage of hClust?
- classical application examples
- limitations/drawbacks of hClust
- short description of the algorithm (maybe with flowchart visualization)
namespace FSharp
--------------------
namespace Microsoft.FSharp
val char : value:'T -> char (requires member op_Explicit)
<summary>Converts the argument to character. Numeric inputs are converted according to the UTF-16 encoding for characters. String inputs must be exactly one character long. For other input types the operation requires an appropriate static conversion method on the input type.</summary>
<param name="value">The input value.</param>
<returns>The converted char.</returns>
--------------------
[<Struct>] type char = System.Char
<summary>An abbreviation for the CLI type <see cref="T:System.Char" />.</summary>
<category>Basic Types</category>
val seq : sequence:seq<'T> -> seq<'T>
<summary>Builds a sequence using sequence expression syntax</summary>
<param name="sequence">The input sequence.</param>
<returns>The result sequence.</returns>
--------------------
type seq<'T> = System.Collections.Generic.IEnumerable<'T>
<summary>An abbreviation for the CLI type <see cref="T:System.Collections.Generic.IEnumerable`1" /></summary>
<remarks> See the <see cref="T:Microsoft.FSharp.Collections.SeqModule" /> module for further operations related to sequences. See also <a href="https://docs.microsoft.com/dotnet/fsharp/language-reference/sequences">F# Language Guide - Sequences</a>. </remarks>
<summary>Provides static methods for the creation, copying, deletion, moving, and opening of a single file, and aids in the creation of <see cref="T:System.IO.FileStream" /> objects.</summary>
<summary>Negate a logical value. Not True equals False and not False equals True</summary>
<param name="value">The value to negate.</param>
<returns>The result of the negation.</returns>
<summary>Gets a value that indicates whether the current stream position is at the end of the stream.</summary>
<exception cref="T:System.ObjectDisposedException">The underlying stream has been disposed.</exception>
<returns><see langword="true" /> if the current stream position is at the end of the stream; otherwise <see langword="false" />.</returns>
System.String.Split(separator: string [], options: System.StringSplitOptions) : string []
System.String.Split(separator: string,?options: System.StringSplitOptions) : string []
System.String.Split(separator: char [], options: System.StringSplitOptions) : string []
System.String.Split(separator: char [], count: int) : string []
System.String.Split(separator: char,?options: System.StringSplitOptions) : string []
System.String.Split(separator: string [], count: int, options: System.StringSplitOptions) : string []
System.String.Split(separator: string, count: int,?options: System.StringSplitOptions) : string []
System.String.Split(separator: char [], count: int, options: System.StringSplitOptions) : string []
System.String.Split(separator: char, count: int,?options: System.StringSplitOptions) : string []
module Seq from Plotly.NET
--------------------
module Seq from FSharpx.Collections
<summary> Extensions for F#'s Seq module. </summary>
--------------------
module Seq from FSharpAux
--------------------
module Seq from FSharp.Stats
<summary> Module to compute common statistical measure </summary>
--------------------
module Seq from Microsoft.FSharp.Collections
<summary>Contains operations for working with values of type <see cref="T:Microsoft.FSharp.Collections.seq`1" />.</summary>
<summary>Returns a sequence that skips N elements of the underlying sequence and then yields the remaining elements of the sequence.</summary>
<param name="count">The number of items to skip.</param>
<param name="source">The input sequence.</param>
<returns>The result sequence.</returns>
<exception cref="T:System.ArgumentNullException">Thrown when the input sequence is null.</exception>
<exception cref="T:System.InvalidOperationException">Thrown when count exceeds the number of elements in the sequence.</exception>
<summary>Builds a new collection whose elements are the results of applying the given function to each of the elements of the collection. The given function will be applied as elements are demanded using the <c>MoveNext</c> method on enumerators retrieved from the object.</summary>
<remarks>The returned sequence may be passed between threads safely. However, individual IEnumerator values generated from the returned sequence should not be accessed concurrently.</remarks>
<param name="mapping">A function to transform items from the input sequence.</param>
<param name="source">The input sequence.</param>
<returns>The result sequence.</returns>
<exception cref="T:System.ArgumentNullException">Thrown when the input sequence is null.</exception>
val float : value:'T -> float (requires member op_Explicit)
<summary>Converts the argument to 64-bit float. This is a direct conversion for all primitive numeric types. For strings, the input is converted using <c>Double.Parse()</c> with InvariantCulture settings. Otherwise the operation requires an appropriate static conversion method on the input type.</summary>
<param name="value">The input value.</param>
<returns>The converted float</returns>
--------------------
[<Struct>] type float = System.Double
<summary>An abbreviation for the CLI type <see cref="T:System.Double" />.</summary>
<category>Basic Types</category>
--------------------
type float<'Measure> = float
<summary>The type of double-precision floating point numbers, annotated with a unit of measure. The unit of measure is erased in compiled code and when values of this type are analyzed using reflection. The type is representationally equivalent to <see cref="T:System.Double" />.</summary>
<category index="6">Basic Types with Units of Measure</category>
<summary>Builds an array from the given collection.</summary>
<param name="source">The input sequence.</param>
<returns>The result array.</returns>
<exception cref="T:System.ArgumentNullException">Thrown when the input sequence is null.</exception>
<summary> Module to compute common statistical measure on array </summary>
<summary> Shuffels the input array (method: Fisher-Yates) </summary>
module Array from FSharpx.Collections
<summary> Extensions for F#'s Array module. </summary>
--------------------
module Array from FSharpAux
--------------------
module Array from FSharp.Stats
<summary> Module to compute common statistical measure on array </summary>
--------------------
module Array from Microsoft.FSharp.Collections
<summary>Contains operations for working with arrays.</summary>
<remarks> See also <a href="https://docs.microsoft.com/dotnet/fsharp/language-reference/arrays">F# Language Guide - Arrays</a>. </remarks>
<summary>Builds a new array whose elements are the results of applying the given function to each of the elements of the array. The integer index passed to the function indicates the index of element being transformed.</summary>
<param name="mapping">The function to transform elements and their indices.</param>
<param name="array">The input array.</param>
<returns>The array of transformed elements.</returns>
<exception cref="T:System.ArgumentNullException">Thrown when the input array is null.</exception>
<summary>Print to a string using the given format.</summary>
<param name="format">The formatter.</param>
<returns>The formatted result.</returns>
<summary>Splits an array of pairs into two arrays.</summary>
<param name="array">The input array.</param>
<returns>The two arrays.</returns>
<exception cref="T:System.ArgumentNullException">Thrown when the input array is null.</exception>
module PriorityQueue from FSharpx.Collections
--------------------
type PriorityQueue<'T (requires comparison)> = interface IEnumerable new : comparisonF:('T -> float) -> PriorityQueue<'T> + 1 overload member Dequeue : unit -> 'T * PriorityQueue<'T> member Insert : t:'T -> unit member RemoveElement : t:'T -> unit member RemoveElementsBy : predicate:('T -> bool) -> unit member UpdateBy : updateElementFunction:('T -> 'T) -> unit member UpdateElement : t:'T -> newt:'T -> unit member Elements : 'T [] member GetHead : 'T
--------------------
new : comparisonF:('T -> float) -> PriorityQueue<'T>
new : values:'T [] * comparisonF:('T -> float) -> PriorityQueue<'T>
<summary>Sorts the elements of an array, in descending order, using the given projection for the keys and returning a new array. Elements are compared using <see cref="M:Microsoft.FSharp.Core.Operators.compare" />.</summary>
<remarks>This is not a stable sort, i.e. the original order of equal elements is not necessarily preserved. For a stable sort, consider using <see cref="M:Microsoft.FSharp.Collections.SeqModule.Sort" />.</remarks>
<param name="projection">The function to transform array elements into the type that is compared.</param>
<param name="array">The input array.</param>
<returns>The sorted array.</returns>
<summary>Returns an empty array of the given type.</summary>
<returns>The empty array.</returns>
<summary>Exposes an enumerator, which supports a simple iteration over a non-generic collection.</summary>
<summary>Builds a new array whose elements are the results of applying the given function to each of the elements of the array.</summary>
<param name="mapping">The function to transform elements of the array.</param>
<param name="array">The input array.</param>
<returns>The array of transformed elements.</returns>
<exception cref="T:System.ArgumentNullException">Thrown when the input array is null.</exception>
<summary>Returns a new collection containing only the elements of the collection for which the given predicate returns "true".</summary>
<param name="predicate">The function to test the input elements.</param>
<param name="array">The input array.</param>
<returns>An array containing the elements for which the given predicate returns true.</returns>
<exception cref="T:System.ArgumentNullException">Thrown when the input array is null.</exception>
<summary>Returns the first element of the array.</summary>
<param name="array">The input array.</param>
<returns>The first element of the array.</returns>
<exception cref="T:System.ArgumentNullException">Thrown when the input array is null.</exception>
<exception cref="T:System.ArgumentException">Thrown when the input array is empty.</exception>
<summary>Returns a new array containing the elements of the original except the first element.</summary>
<param name="array">The input array.</param>
<exception cref="T:System.ArgumentException">Thrown when the array is empty.</exception>
<exception cref="T:System.ArgumentNullException">Thrown when the input array is null.</exception>
<returns>A new array containing the elements of the original except the first element.</returns>
<summary>Builds a new array that contains the elements of the first array followed by the elements of the second array.</summary>
<param name="array1">The first input array.</param>
<param name="array2">The second input array.</param>
<returns>The resulting array.</returns>
<exception cref="T:System.ArgumentNullException">Thrown when either of the input arrays is null.</exception>
<summary>An abbreviation for the CLI type <see cref="T:System.Boolean" />.</summary>
<category>Basic Types</category>
inverse of distance
list of source cluster indices
val int : value:'T -> int (requires member op_Explicit)
<summary>Converts the argument to signed 32-bit integer. This is a direct conversion for all primitive numeric types. For strings, the input is converted using <c>Int32.Parse()</c> with InvariantCulture settings. Otherwise the operation requires an appropriate static conversion method on the input type.</summary>
<param name="value">The input value.</param>
<returns>The converted int</returns>
--------------------
[<Struct>] type int = int32
<summary>An abbreviation for the CLI type <see cref="T:System.Int32" />.</summary>
<category>Basic Types</category>
--------------------
type int<'Measure> = int
<summary>The type of 32-bit signed integer numbers, annotated with a unit of measure. The unit of measure is erased in compiled code and when values of this type are analyzed using reflection. The type is representationally equivalent to <see cref="T:System.Int32" />.</summary>
<category>Basic Types with Units of Measure</category>
<summary>The type of immutable singly-linked lists. </summary>
<remarks>See the <see cref="T:Microsoft.FSharp.Collections.ListModule" /> module for further operations related to lists. Use the constructors <c>[]</c> and <c>::</c> (infix) to create values of this type, or the notation <c>[1; 2; 3]</c>. Use the values in the <c>List</c> module to manipulate values of this type, or pattern match against the values directly. See also <a href="https://docs.microsoft.com/dotnet/fsharp/language-reference/lists">F# Language Guide - Lists</a>. </remarks>
list of target cluster indices
Type to store similarities
module List from FSharpx.Collections
<summary> Extensions for F#'s List module. </summary>
--------------------
module List from FSharpAux
--------------------
module List from FSharp.Stats
<summary> Module to compute common statistical measure on list </summary>
--------------------
module List from Microsoft.FSharp.Collections
<summary>Contains operations for working with values of type <see cref="T:Microsoft.FSharp.Collections.list`1" />.</summary>
<namespacedoc><summary>Operations for collections such as lists, arrays, sets, maps and sequences. See also <a href="https://docs.microsoft.com/dotnet/fsharp/language-reference/fsharp-collection-types">F# Collection Types</a> in the F# Language Guide. </summary></namespacedoc>
--------------------
type List<'T> = | ( [] ) | ( :: ) of Head: 'T * Tail: 'T list interface IReadOnlyList<'T> interface IReadOnlyCollection<'T> interface IEnumerable interface IEnumerable<'T> member GetReverseIndex : rank:int * offset:int -> int member GetSlice : startIndex:int option * endIndex:int option -> 'T list static member Cons : head:'T * tail:'T list -> 'T list member Head : 'T member IsEmpty : bool member Item : index:int -> 'T with get ...
<summary>The type of immutable singly-linked lists.</summary>
<remarks>Use the constructors <c>[]</c> and <c>::</c> (infix) to create values of this type, or the notation <c>[1;2;3]</c>. Use the values in the <c>List</c> module to manipulate values of this type, or pattern match against the values directly. </remarks>
<exclude />
<summary>Tests if the list contains the specified element.</summary>
<param name="value">The value to locate in the input list.</param>
<param name="source">The input list.</param>
<returns>True if the input list contains the specified element; false otherwise.</returns>
type IntervalHeap<'T> = inherit CollectionValueBase<'T> interface IPriorityQueue<'T> interface IExtensible<'T> interface ICollectionValue<'T> interface IEnumerable<'T> interface IEnumerable interface IShowable interface IFormattable new :?memoryType: MemoryType -> unit + 4 overloads member Add : item: 'T -> bool + 1 overload ...
<summary> A priority queue class based on an interval heap data structure. </summary>
<typeparam name="T">The item type</typeparam>
--------------------
IntervalHeap(?memoryType: MemoryType) : IntervalHeap<'T>
IntervalHeap(comparer: System.Collections.Generic.IComparer<'T>,?memoryType: MemoryType) : IntervalHeap<'T>
IntervalHeap(capacity: int,?memoryType: MemoryType) : IntervalHeap<'T>
IntervalHeap(capacity: int, comparer: System.Collections.Generic.IComparer<'T>,?memoryType: MemoryType) : IntervalHeap<'T>
<summary> It specifies the memory type strategy of the internal enumerator implemented to iterate over the collection. </summary>
<summary> Normal is the usual operator type. A new instance of an enumerator is always returned for multithread safety purposes. </summary>
IntervalHeap.FindMax(handle: byref<IPriorityQueueHandle<Neighbour>>) : Neighbour
IntervalHeap.DeleteMax(handle: byref<IPriorityQueueHandle<Neighbour>>) : Neighbour